Annotation-Based Integration
Using @TrialsTest for simple, declarative property tests
Artifact Required:
libraryDependencies += "com.sageserpent" %% "americium-junit5" % "2.0.0"
Table of contents
- Philosophy
- Package Imports
@TrialsTest- The Tiers Test Revisited- How It Works
- IDE Integration
- Tuple Unpacking
- Multiple Trials with
.and() - Test Lifecycle
- Static vs Non-Static
- Shrinkage in Action
- Recipe Reproduction
- The Run Database (Again)
@ConfiguredTrialsTest
Philosophy
Americium takes a lean and mean approach - it supplies test cases and shrinks them down, but doesn’t dictate how you structure tests, what assertions you use, or how you manage setup and teardown.
However, JUnit5 is ubiquitous in Java development, and your IDE likely has excellent support for it. The @ParameterizedTest annotation lets you run tests multiple times with different arguments - sounds familiar, right?
JUnit5’s built-in parameterized testing is rudimentary - you supply test cases manually or generate them in ad-hoc ways; shrinkage is not supported, let alone replay of shrunk failing test cases.
Americium’s JUnit5 integration gives you the best of both worlds: property-based testing with shrinkage, plus IDE integration that shows individual trial runs, shrinkage attempts, and lets you replay specific cases.
Package Imports
Java:
import com.sageserpent.americium.junit5.TrialsTest;
import com.sageserpent.americium.junit5.ConfiguredTrialsTest;
Scala:
import com.sageserpent.americium.junit5.*
@TrialsTest - The Tiers Test Revisited
Let’s integrate the Tiers example from earlier with JUnit5:
import com.sageserpent.americium.junit5.TrialsTest;
import static com.sageserpent.americium.java.Trials.api;
public class TiersTest {
private static final Trials<ImmutableList<Integer>> queryValueLists =
api().integers(-1000, 1000)
.immutableLists()
.filter(list -> !list.isEmpty());
private static final Trials<Tuple2<ImmutableList<Integer>,
ImmutableList<Integer>>> testCases =
queryValueLists.flatMap(queryValues -> {
final int minimumQueryValue =
queryValues.stream().min(Integer::compareTo).get();
final Trials<ImmutableList<Integer>> backgrounds =
api().integers(Integer.MIN_VALUE, minimumQueryValue - 1)
.immutableLists();
final List<Trials<ImmutableList<Integer>>> sectionTrials =
queryValues.stream()
.flatMap(queryValue ->
Stream.of(
api().only(ImmutableList.of(queryValue)),
backgrounds))
.collect(Collectors.toList());
sectionTrials.add(0, backgrounds);
final Trials<ImmutableList<Integer>> feedSequences =
api().immutableLists(sectionTrials).map(sections -> {
final ImmutableList.Builder<Integer> builder =
ImmutableList.builder();
sections.forEach(builder::addAll);
return builder.build();
});
return feedSequences.map(feedSequence ->
Tuple.tuple(queryValues, feedSequence));
});
@TrialsTest(trials = "testCases", casesLimit = 30)
void tiersShouldRetainTheLargestElements(
Tuple2<ImmutableList<Integer>, ImmutableList<Integer>> testCase) {
final ImmutableList<Integer> queryValues = testCase._1();
final ImmutableList<Integer> feedSequence = testCase._2();
System.out.format("Query values: %s, feed sequence: %s\n",
queryValues, feedSequence);
final int worstTier = queryValues.size();
final Tiers<Integer> tiers = new Tiers<>(worstTier);
feedSequence.forEach(tiers::add);
final ImmutableList.Builder<Integer> builder =
ImmutableList.builder();
int tier = worstTier;
int previousTierOccupant = Integer.MIN_VALUE;
do {
final Integer tierOccupant = tiers.at(tier).get();
assertThat(tierOccupant, greaterThanOrEqualTo(previousTierOccupant));
builder.add(tierOccupant);
previousTierOccupant = tierOccupant;
} while (1 < tier--);
final ImmutableList<Integer> arrangedByRank = builder.build();
assertThat(arrangedByRank, containsInAnyOrder(queryValues.toArray()));
}
}
How It Works
We’ve defined trials instances as final static fields in the test class - they’re immutable, so this fits nicely.
The test method is annotated with @TrialsTest instead of JUnit5’s usual @Test:
@TrialsTest(trials = "testCases", casesLimit = 30)
void tiersShouldRetainTheLargestElements(
Tuple2<ImmutableList<Integer>, ImmutableList<Integer>> testCase) {
// ...
}
Annotation Parameters
trials- Names the static field containing theTrialsinstance (analogous to@MethodSource)casesLimit- Same as.withLimit()complexity- Optional, same as.withComplexityLimit()shrinkageAttempts- Optional, same as.withShrinkageAttemptsLimit()
If you’ve used @ParameterizedTest before, this should feel familiar - but simpler, because @TrialsTest does everything in one annotation (no need for separate @ValueSource or @MethodSource).
IDE Integration
When you run this test in IntelliJ (or any other IDE that integrates with JUnit5), you’ll see:
- ✅ Each trial run listed individually
- ✅ Test case values for each trial
- ✅ Output from each trial (
System.outvisible per-trial) - ✅ Right-click to re-run individual trials
- ✅ Shrinkage attempts shown when tests fail
This makes debugging property tests much easier - you can see exactly which trial failed and re-run just that one!
Tuple Unpacking
Having to extract values from a Tuple2 is clunky:
final ImmutableList<Integer> queryValues = testCase._1();
final ImmutableList<Integer> feedSequence = testCase._2();
Americium’s JUnit5 integration can automatically unpack tuples into separate parameters:
@TrialsTest(trials = "testCases", casesLimit = 10)
void tiersShouldRetainTheLargestElements(
ImmutableList<Integer> queryValues, // Unpacked from tuple!
ImmutableList<Integer> feedSequence) { // Unpacked from tuple!
System.out.format("Query values: %s, feed sequence: %s\n",
queryValues, feedSequence);
// No need to call ._1() and ._2() !
// ...
}
Much cleaner! The integration automatically matches the tuple elements to the method parameters.
Multiple Trials with .and()
You can supply multiple independent trials directly in the annotation:
public class SetMembershipPredicateTest {
private static final Trials<ImmutableList<Long>> lists =
Trials.api().longs().immutableLists();
private static final Trials<Long> longs =
Trials.api().longs();
@TrialsTest(
trials = {"lists", "longs", "lists"}, // Three independent trials!
casesLimit = 10
)
void setMembershipShouldBeRecognised(
ImmutableList<Long> leftHandList,
Long additionalLongToSearchFor,
ImmutableList<Long> rightHandList) {
final Predicate<Long> systemUnderTest =
new PoorQualitySetMembershipPredicate(
ImmutableList.builder()
.addAll(leftHandList)
.add(additionalLongToSearchFor)
.addAll(rightHandList)
.build());
assertThat(systemUnderTest.test(additionalLongToSearchFor), is(true));
}
}
The three trials are automatically ganged together (as if you’d called .and()) and unpacked into the three parameters!
Test Lifecycle
@BeforeEach and @AfterEach
These run per-trial - so each trial gets a clean environment:
public class MyTest {
private SystemUnderTest system;
@BeforeEach
void setUp() {
system = new SystemUnderTest(); // Fresh for each trial!
}
@AfterEach
void tearDown() {
system.cleanup(); // Clean up after each trial
}
@TrialsTest(trials = "testCases", casesLimit = 100)
void testSomething(TestCase testCase) {
// 'system' is fresh for this trial
}
}
@BeforeAll and @AfterAll
These run once per test suite - before all trials start and after all trials complete:
@BeforeAll
static void setUpClass() {
// Runs once before any trials
}
@AfterAll
static void tearDownClass() {
// Runs once after all trials
}
Static vs Non-Static
By default, JUnit5 uses per-method lifecycle, which means:
- The test class is instantiated once per test method
- Trials fields must be
static - Setup/teardown methods annotated with
@BeforeEach/@AfterEachmust bestatic
Using Non-Static Fields
If you want non-static trials fields, use per-class lifecycle:
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
public class MyTest {
private final Trials<Integer> integers = // Non-static!
Trials.api().integers();
@TrialsTest(trials = "integers", casesLimit = 100)
void testSomething(Integer value) {
// ...
}
}
Now the test class is instantiated once and reused for all test methods.
Shrinkage in Action
Let’s see shrinkage at work, we’ll run SetMembershipPredicateTest:
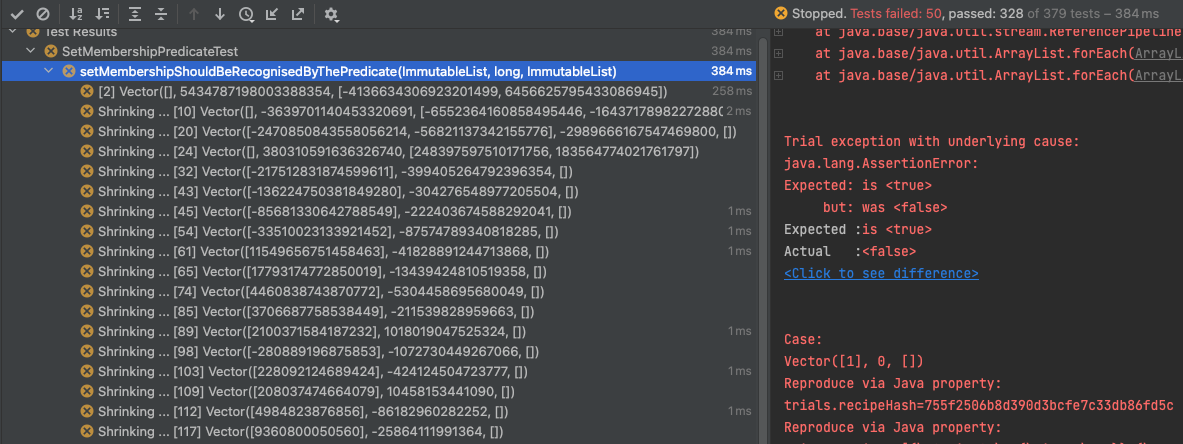
When you run this in your IDE (the screenshot above is from IntelliJ), you’ll see:
- Trial 1 passes
- Trial 2 fails ← Initial failure detected
- Shrinkage attempts shown in IDE (grayed out or marked differently)
- Final shrunk case shown with clear failure message
Recipe Reproduction
When a test fails, you’ll see recipe information in the output:
Recipe hash for reproduction: a1b2c3d4e5f6...
Recipe JSON: [{"ChoiceOf":{"index":1}}, ...]
Use these to reproduce failures:
# Local reproduction (recipe hash)
-Dtrials.recipeHash=a1b2c3d4e5f6...
# Portable reproduction (recipe JSON)
-Dtrials.recipe='[{"ChoiceOf":{"index":1}}, ...]'
This works exactly the same with JUnit5 integration as with standalone .supplyTo().
The Run Database (Again)
Similarly to recipes, replay information is stored in an additional database located at:
{temp-dir}/{database-name}-junit5/
Where:
temp-dir- Java system propertyjava.io.tmpdirdatabase-name- Java propertytrials.runDatabase(default:trialsRunDatabase)
If you’re running tests from an IDE, you can directly replay the maximally shrunk test case; you may prefer this over using a recipe.
@ConfiguredTrialsTest
For more advanced configuration, use @ConfiguredTrialsTest with SupplyToSyntax:
public class MyTest {
private static final SupplyToSyntax<TestCase> configuredTrials =
Trials.api()
.integers()
.immutableLists()
.withStrategy(cycle ->
cycle.isInitial
? CasesLimitStrategy.timed(Duration.ofSeconds(10))
: CasesLimitStrategy.counted(50, 0.2))
.withComplexityLimit(75)
.withShrinkageAttemptsLimit(30);
@ConfiguredTrialsTest(trials = "configuredTrials")
void testSomething(ImmutableList<Integer> testCase) {
// ...
}
}
Differences from @TrialsTest
- Uses
SupplyToSyntaxinstead ofTrials - Configuration is in the field definition (
.withStrategy(), etc.) - No
casesLimitparameter (already configured) - Only one trials instance allowed (can’t use array like
{"trials1", "trials2"})
If you need multiple trials, gang them with .and() first:
private static final SupplyToSyntax<Tuple3<Integer, String, Boolean>> ganged =
Trials.api().integers()
.and(Trials.api().strings())
.and(Trials.api().booleans())
.withLimit(100)
.withComplexityLimit(50);
@ConfiguredTrialsTest(trials = "ganged")
void test(Integer num, String str, Boolean flag) {
// Tuple3 automatically unpacked!
}
Key Takeaways
@TrialsTest- Simple annotation-based integrationtrialsparameter - Names a static field containingTrialsinstancecasesLimit,complexity,shrinkageAttempts- Configure inline- Tuple unpacking - Tuples automatically expand into separate parameters
- Multiple trials - Use array:
trials = {"t1", "t2", "t3"}- Lifecycle hooks -
@BeforeEach/@AfterEachrun per-trial- IDE integration - See individual trials, re-run specific cases
- Shrinkage visualization - Watch shrinkage attempts in IDE
@ConfiguredTrialsTest- UseSupplyToSyntaxfor advanced configuration- Recipe reproduction - Same as standalone (hash or JSON)